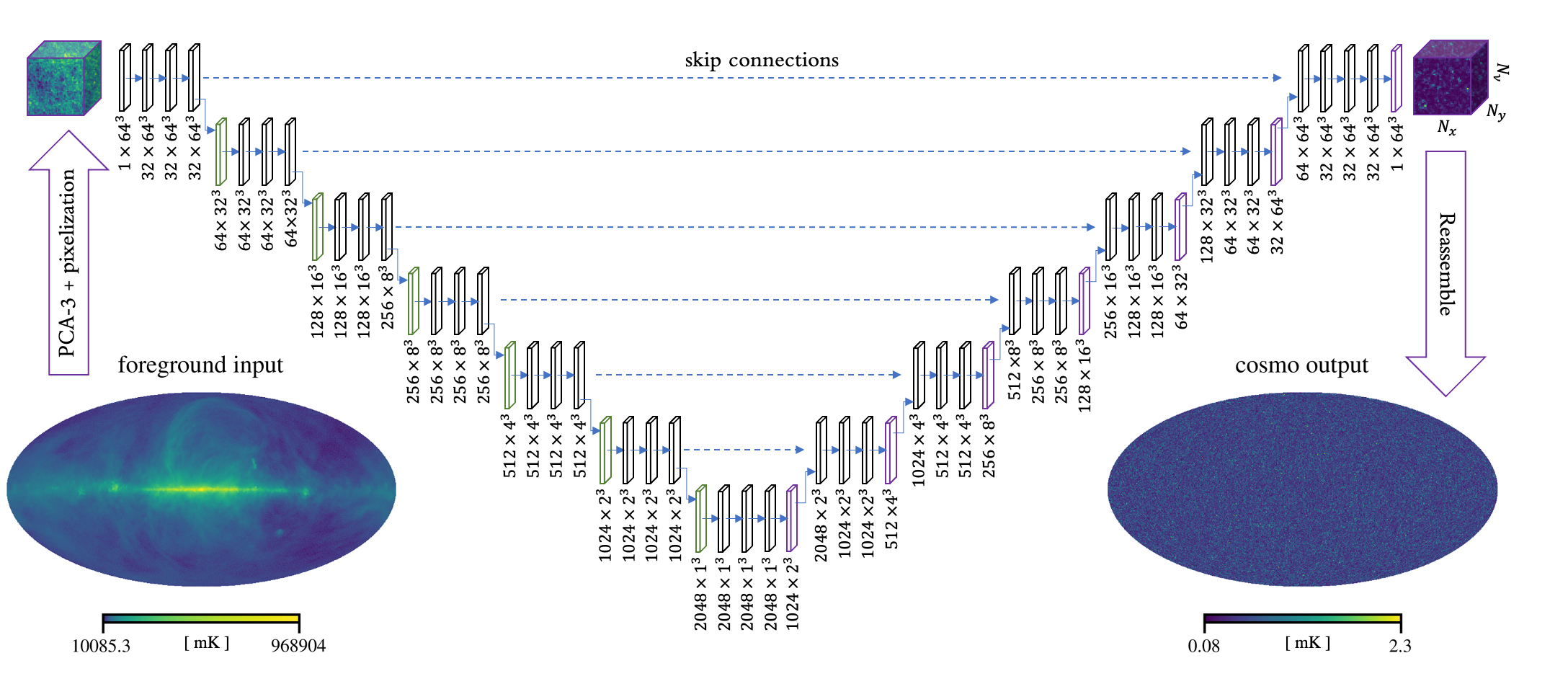
![]()
A straightforward asset bundling plugin for Jekyll, utilizing external asset conversion/minification tool of your choice. The plugin provides asset concatenation for bundling and asset fingerprinting with MD5 digest for cache busting.
There are no runtime dependencies, except for the minification tool used for bundling (fingerprinting has no dependencies).
The plugin requires Jekyll version 3 or 4. It is tested with Ruby MRI 2.7 and later.
The plugin works with Jekyll’s watch mode (auto-regeneration, Jekyll
option --watch), but not with incremental feature enabled (Jekyll
option --incremental).
Minibundle plugin does not affect the behavior of Jekyll’s built-in asset conversion. The plugin is designed to incorporate the results produced by external asset tools only.
There are two features: fingerprinting with MD5 digest over the contents of the asset file (any type of file will do), and asset bundling combined with the first feature.
Asset bundling consists of concatenation and minification. The plugin implements concatenation and leaves choosing the minification tool up to you. UglifyJS is a good and fast minifier, for example. The plugin connects to the minifier with standard unix pipe, feeding asset file contents to it in desired order via standard input, and reads the result from standard output.
Why is this good? A fingerprint in asset’s path is the recommended way to handle caching of static resources, because you can allow browsers and intermediate proxies to cache the asset for a very long time. Calculating MD5 digest over the contents of the file is fast and the resulting digest is reasonably unique to be generated automatically.
Asset bundling is good for reducing the number of requests to the backend upon page load. The minification of stylesheets and JavaScript sources makes asset sizes smaller and thus faster to load over network.
The plugin ships as a RubyGem. To install:
-
Add the following line to the Gemfile of your site:
gem 'jekyll-minibundle'
-
Run
bundle install. -
Instruct Jekyll to load the gem by adding this line to the configuration file of your site (
_config.yml):plugins: - jekyll/minibundle
(Use the
gemskey instead ofpluginsfor Jekyll older than v3.5.0.)
An alternative to using the plugins configuration option is to add the
_plugins/minibundle.rb file to your site project with this line:
require 'jekyll/minibundle'You must allow Jekyll to use custom plugins. That is, do not enable
Jekyll’s safe configuration option.
If you just want to have an MD5 fingerprint in your asset’s path, use
the ministamp Liquid tag in a Liquid template file. For example,
fingerprinting CSS styles:
<link rel="stylesheet" href="{{ site.baseurl }}/{% ministamp _assets/site.css assets/site.css %}" media="screen, projection">When it’s time to render the ministamp tag, the plugin copies the
source file (_assets/site.css, the first tag argument) to the
specified destination path (assets/site.css, the second tag argument)
in Jekyll’s site destination directory. The filename will contain a
fingerprint.
The tag outputs the asset destination path, encoded for HTML, into
Liquid’s template rendering outcome. For example, when site.baseurl is
empty:
<link rel="stylesheet" href="/assets/site-390be921ee0eff063817bb5ef2954300.css" media="screen, projection">Another example, this time fingerprinting an image and using the
absolute_url Liquid filter of Jekyll to render
the absolute URL of the image in the src attribute:
<img src="{{ "https://github.com/" | absolute_url }}{% ministamp _assets/dog.jpg assets/dog.jpg %}" alt="My dog smiling to the camera" title="A photo of my dog" width="195" height="258" />This feature can be combined with asset generation tools external to
Jekyll. For example, you can configure Sass to take input files from
_assets/styles/*.scss and to produce output to _tmp/site.css. Then,
you use the ministamp tag to copy the file with a fingerprint to
Jekyll’s site destination directory:
<link rel="stylesheet" href="{{ site.baseurl }}/{% ministamp _tmp/site.css assets/site.css %}">The argument for the ministamp tag must be in YAML syntax, and
parsing the argument as YAML must result either in a String or a
Hash. What you saw previously was the argument being parsed as a String;
it’s effectively a shorthand version of passing the argument as a Hash
with certain keys. That is, in the following call:
{% ministamp _tmp/site.css assets/site.css %}the argument is a String: "_tmp/site.css assets/site.css". The call is
equivalent to the following call with a Hash argument:
{% ministamp { source_path: _tmp/site.css, destination_path: assets/site.css } %}The Hash argument allows expressing more options and quoting
source_path and destination_path values, if needed.
The supported keys for the Hash argument are:
| Key | Required? | Value type | Value example | Default value | Description |
|---|---|---|---|---|---|
source_path |
yes | string | '_tmp/site.css' |
– | The source path of the asset file, relative to the site directory. |
destination_path |
yes | string | 'assets/site.css' |
– | The destination path of the asset file, relative to Jekyll’s site destination directory. If the value begins with / and render_basename_only is false, ministamp‘s output will begin with /. |
render_basename_only |
no | boolean | true |
false |
If true, ministamp‘s rendered URL will be the basename of the asset destination path. See Separating asset destination path from generated URL for more. |
With a Hash argument, the plugin processes source_path and
destination_path values through a tiny template engine. This allows
you to use Liquid’s variables as input to ministamp tag. An example
with Liquid’s assign tag:
{% assign asset_dir = 'assets' %}
<link rel="stylesheet" href="{% ministamp { source_path: _tmp/site.css, destination_path: '{{ asset_dir }}/site.css' } %}">The above would use assets/site.css as the destination path.
Note that you must quote destination_path‘s value, otherwise YAML does
not recognize it as a proper string.
To refer to Jekyll’s configuration options (_config.yml)
in the template, prefix the variable name with site.. For example, to
refer to baseurl option, use syntax {{ site.baseurl }} in the
template.
See Variable templating for details about the template syntax.
This is a straightforward way to bundle assets with any minification tool that supports reading input from stdin and writing the output to stdout. You write the configuration for input sources directly into the content file where you want the markup tag for the bundle file to appear. The markup tag contains the path to the bundle file, and the Jekyll’s site destination directory will have the bundle file at that path. The path will contain an MD5 fingerprint.
Place the minibundle Liquid block into the Liquid template file
where you want the block’s generated markup to appear. Write bundling
configuration inside the block in YAML syntax. For example, to bundle
a set of JavaScript sources:
{% minibundle js %}
source_dir: _assets/scripts
destination_path: assets/site
baseurl: '{{ site.baseurl }}/'
assets:
- dependency
- app
attributes:
id: my-scripts
async:
{% endminibundle %}
Then, specify the command for launching your favorite minifier in
_config.yml:
baseurl: ''
minibundle:
minifier_commands:
js: node_modules/.bin/uglifyjsWhen it’s time to render the minibundle block, the plugin launches the
minifier and connects to it with a Unix pipe. The plugin feeds the
contents of the asset files in source_dir directory as input to the
minifier (stdin). The feeding order is the order of the files in the
assets key in the block configuration. The plugin expects the minifier
to produce output (stdout) and writes it to the file at
destination_path in Jekyll’s site destination directory. The filename
will contain a fingerprint.
The block outputs <link> (for css type) or <script> (for js
type) HTML element into Liquid’s template rendering outcome. Continuing
the example above, the block’s output will be:
<script src="/assets/site-8e764372a0dbd296033cb2a416f064b5.js" type="text/javascript" id="my-scripts" async></script>You can pass custom attributes, like id="my-scripts" and async
above, to the generated markup with attributes map inside the
minibundle block.
As shown above for the baseurl key, you can use Liquid template syntax
inside the contents of the block. Liquid renders block contents before
the minibundle block gets the turn to render itself. Just ensure that
block contents will result in valid YAML.
For bundling CSS assets, use css as the argument to the minibundle
block:
{% minibundle css %}
source_dir: _assets/styles
destination_path: assets/site
baseurl: '{{ site.baseurl }}/'
assets:
- reset
- common
attributes:
media: screen
{% endminibundle %}
And then specify the minifier command in _config.yml:
minibundle:
minifier_commands:
css: _bin/remove_whitespace
js: node_modules/.bin/uglifyjsUse css or js as the argument to the opening tag, for example {% minibundle css %}.
The block contents must be in YAML syntax. The supported keys are:
| Key | Value type | Value example | Default value | Description |
|---|---|---|---|---|
source_dir |
string | – | '_assets' |
The source directory of assets, relative to the site directory. You can use period (.) to select the site directory itself. |
assets |
array of strings | ['deps/one', 'deps/two', 'app'] |
[] |
Array of assets relative to source_dir directory, without type extension. These are the asset files to be bundled, in order, into one bundle destination file. |
destination_path |
string | – | 'assets/site' |
The destination path of the bundle file, without type extension, relative to Jekyll’s site destination directory. If the value begins with / and baseurl is empty, baseurl will be set to "https://github.com/" implicitly. |
baseurl |
string | '{{ site.baseurl }}/' |
'' |
If nonempty, the bundle destination URL inside minibundle‘s rendered HTML element will be this value prepended to the destination path of the bundle file. Ignored if destination_baseurl is nonempty. |
destination_baseurl |
string | '{{ site.cdn_baseurl }}/' |
'' |
If nonempty, the bundle destination URL inside minibundle‘s rendered HTML element will be this value prepended to the basename of the bundle destination path. See Separating asset destination path from generated URL for more. |
attributes |
map of keys to string values | {id: my-link, media: screen} |
{} |
Custom HTML element attributes to be added to minibundle‘s rendered HTML element. |
minifier_cmd |
string | 'node_modules/.bin/uglifyjs' |
– | Minifier command specific to this bundle. See Minifier command specification for more. |
You can specify minifier commands in three places:
-
In
_config.yml(as shown earlier):minibundle: minifier_commands: css: _bin/remove_whitespace js: node_modules/.bin/uglifyjs
-
As environment variables:
export JEKYLL_MINIBUNDLE_CMD_CSS=_bin/remove_whitespace export JEKYLL_MINIBUNDLE_CMD_JS="node_modules/.bin/uglifyjs"
-
Inside the
minibundleblock withminifier_cmdoption, allowing blocks to have different commands from each other:{% minibundle js %} source_dir: _assets/scripts destination_path: assets/site minifier_cmd: node_modules/.bin/uglifyjs assets: - dependency - app attributes: id: my-scripts {% endminibundle %}
These ways of specification are listed in increasing order of
specificity. Should multiple commands apply to a block, the most
specific one wins. For example, the minifier_cmd option inside the {% minibundle js }% block overrides the setting in the
$JEKYLL_MINIBUNDLE_CMD_JS environment variable.
It’s recommended that you exclude the files you use as asset sources from Jekyll itself. Otherwise, you end up with duplicate files in the site destination directory.
For example, in the following snippet we’re using assets/src.css as
asset source to ministamp tag:
begin{{ var }}end results in beginfooend.
The engine supports variable substitution only. It does not support other expressions. If you need to, you can write complex expressions in Liquid, store the result to a variable, and use the variable in the template.
If you need literal { or } characters in the template, you can
escape them with backslash. For example, \{ results in { in the
output. To output backslash character itself, write it twice: \\
results in \ in the output.
Inside variable subsitution (between {{ and }}), anything before the
closing }} tag is interpreted as part of the variable name, except
that the engine removes any leading and trailing whitespace from the
name. For example, in the template {{ var } }}, var } is treated as
the name of the variable.
A reference to undefined variable results in empty string. For example,
begin{{ nosuch }}end will output beginend if there’s no variable
named nosuch.
Use the render_basename_only: true option of the ministamp tag and
the destination_baseurl option of the minibundle block to separate
the destination path of the asset file from the generated URL of the
asset. This allows you to serve the asset from a separate domain, for
example.
Example usage, with the following content in _config.yml:
cdn_baseurl: 'https://cdn.example.com'For the ministamp tag:
<link rel="stylesheet" href="{{ site.cdn_baseurl }}/css/{% ministamp { source_path: '_tmp/site.css', destination_path: assets/site.css, render_basename_only: true } %}">The asset file will be in Jekyll’s site destination directory with path
assets/site-ff9c63f843b11f9c3666fe46caaddea8.css, and Liquid’s
rendering will result in:
<link rel="stylesheet" href="https://cdn.example.com/css/site-ff9c63f843b11f9c3666fe46caaddea8.css">For the minibundle block:
{% minibundle js %}
source_dir: _assets/scripts
destination_path: assets/site
destination_baseurl: '{{ site.cdn_baseurl }}/js/'
assets:
- dependency
- app
{% endminibundle %}The bundle file will be in Jekyll’s site destination directory with path
assets/site-4782a1f67803038d4f8351051e67deb8.js, and Liquid’s
rendering will result in:
<script type="text/javascript" src="https://cdn.example.com/js/site-4782a1f67803038d4f8351051e67deb8.js"></script>Use Liquid’s capture block to store output
rendered inside the block to a variable, as a string. Then you can
process the string as you like.
For example:
{% capture site_css %}{% ministamp _assets/site.css assets/site.css %}{% endcapture %}
<link rel="stylesheet" href="{{ site_css | remove_first: "assets/" }}">Liquid’s rendering outcome:
<link rel="stylesheet" href="site-390be921ee0eff063817bb5ef2954300.css">See the sources of an example site.
The plugin does not work with Jekyll’s incremental rebuild feature
(Jekyll option --incremental).
MIT. See LICENSE.txt.
 https://github.com/tkareine/jekyll-minibundle
https://github.com/tkareine/jekyll-minibundle