
This matlab classifier aims to distinguish normal speech, abusive/angry/violate speech and environmental noise.
The speech/noise classifier is based on audio features Zero-Cross-Rate and Spectral Flux, the abusive speech classifier is based on features Mel-frequency cepstral coefficients and Harmonic Ratio. The classifier uses K-Nearest-Neighbors.
SVM and decision tree are also tested, but are not chosen due to poor performance.
My training data, reports and other files can be found at this dropbox link: https://www.dropbox.com/sh/s4fho148k6l3npz/AADJnnfqUJlQU_0QIEMbSsfCa?dl=0
Matlab R2014 or higher (not quite sure…)
Most bugs in old versions are due to different names of functions. For example, wavread is used in old version rather than audioread. To check if your version of matlab is suitable, type in your matlab console
help audioread
If the explanation for ‘audioread’ apears, then continue to type
help audiorecorder
If the explanations for two functions are listed, then you have them in your current matlab, and you can run my code now.
Download my matlab code
git clone https://github.com/zhiyuan8/speech_detection.git
Change your Matlab working directory to the folder where you download my code. Open my_code_real_time.m file. Go to load KNN model and do normalization section, paste the code in your matlab console.
clear all;% close worksheet
clc;% close console
fclose('all'); % close all open files
modelSpeech_Non = 'model_11_11_speech_noise_S_Flux_ZCR_filter_6stats.mat';
modelSpeech_Abuse = 'model_11_12_speech_abuse_MFCC_filter_6stats.mat';
if strfind(modelSpeech_Non, 'filter')
filter_dec1 = true;
else
filter_dec1 = false;
end
if (strfind(modelSpeech_Abuse, 'filter'))
filter_dec2 = true;
else
filter_dec2 = false;
end
KNN_Non=10; %
KNN_Abuse=10;
durationSecs=20;
Fs=16000; %Keep consistant with 16 kHz that I use for training datasets
nbit=16; %Keep consistant with 16 nbits that I use for training datasets
The only part you shall change is ‘durationSecs’ which indicates the length of this audio recording. I set it as 20s. The codes above tells matlab what features you choose for detection, as well as parameters for audio recorder and classifier.
Then, paste the code above in matlab console to launch detection:
[recorder,samples,label1, P1, trainchosen1, label2, P2, trainchosen2, calc_time] ...
= Real_Time_KNN(Fs,nbit, durationSecs,modelSpeech_Non,modelSpeech_Abuse,...
KNN_Non,KNN_Abuse,filter_dec1,filter_dec2);
A figure will be generated and you can speak to your computer and see performance of this classifier.
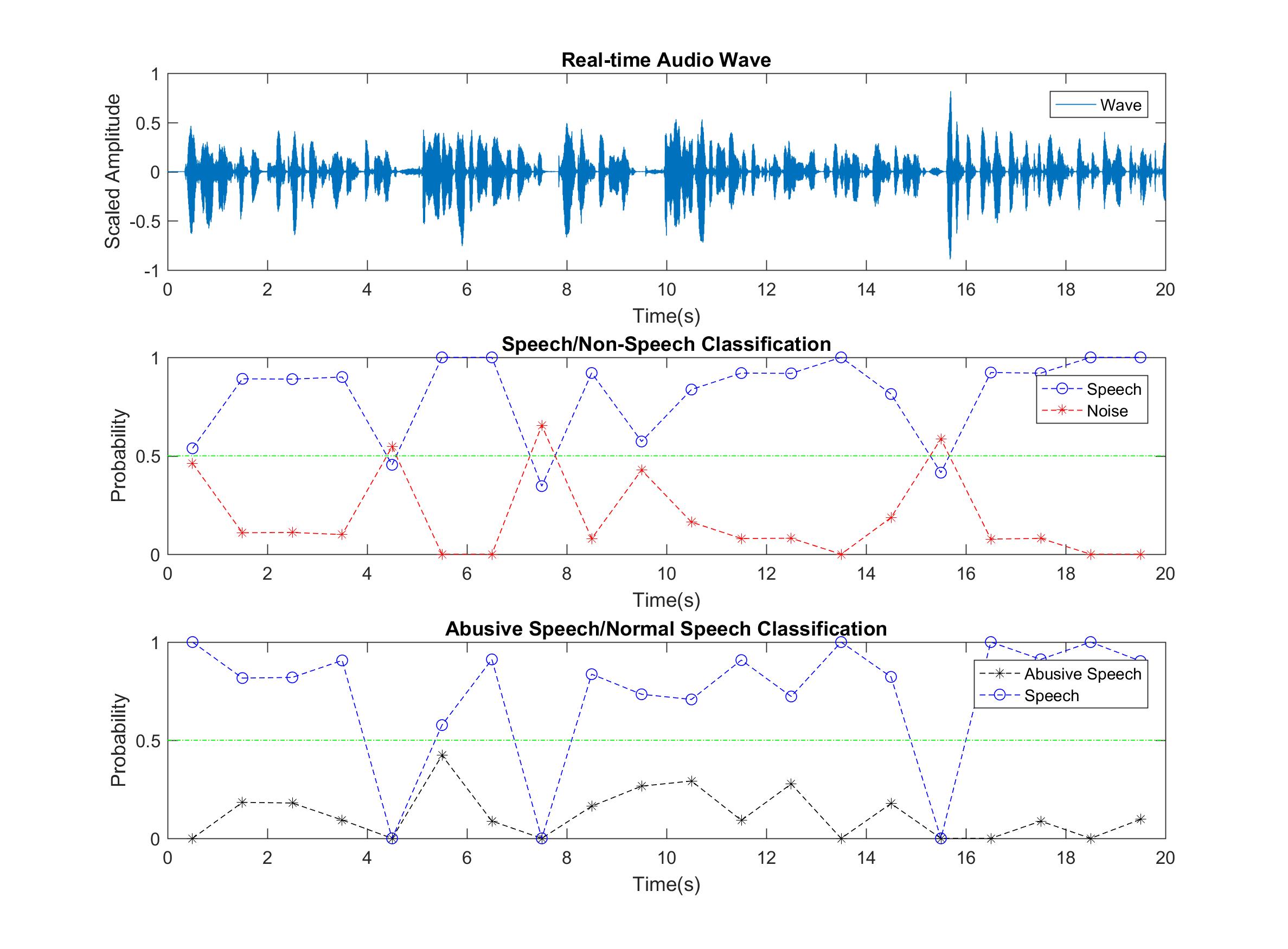
1.Open Matlab, Normally Speak to microphone. Speech identification works well and can identify my speech. When there is a short break between my two sentences, the classifier can find that short blank.

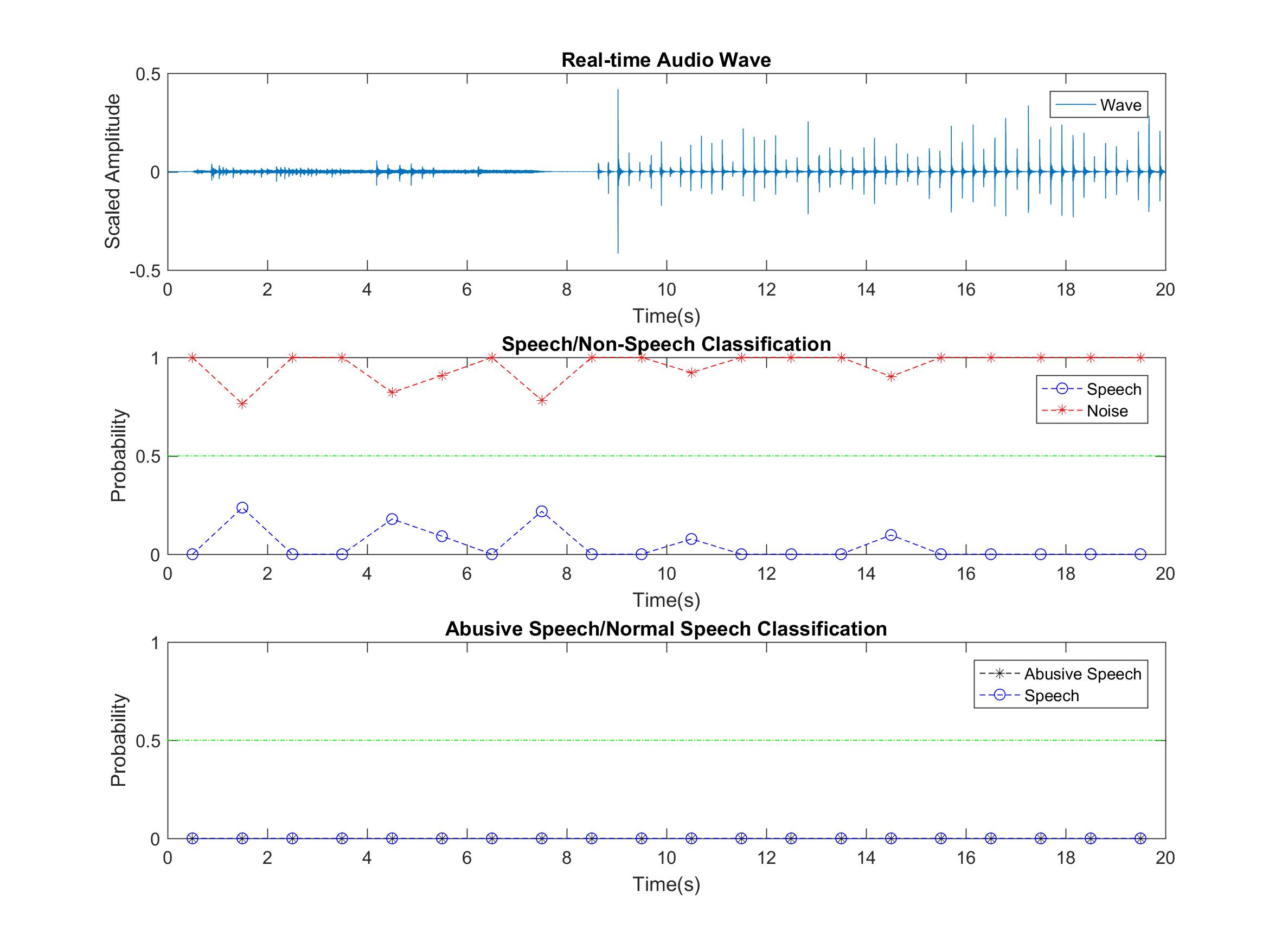
2.Open Matlab, make some noises. Noise identification works well. At first some high-frequent noises (clapping table, knock keyboards) are hard to tell, but after adding a dB filter, the classifier works better.

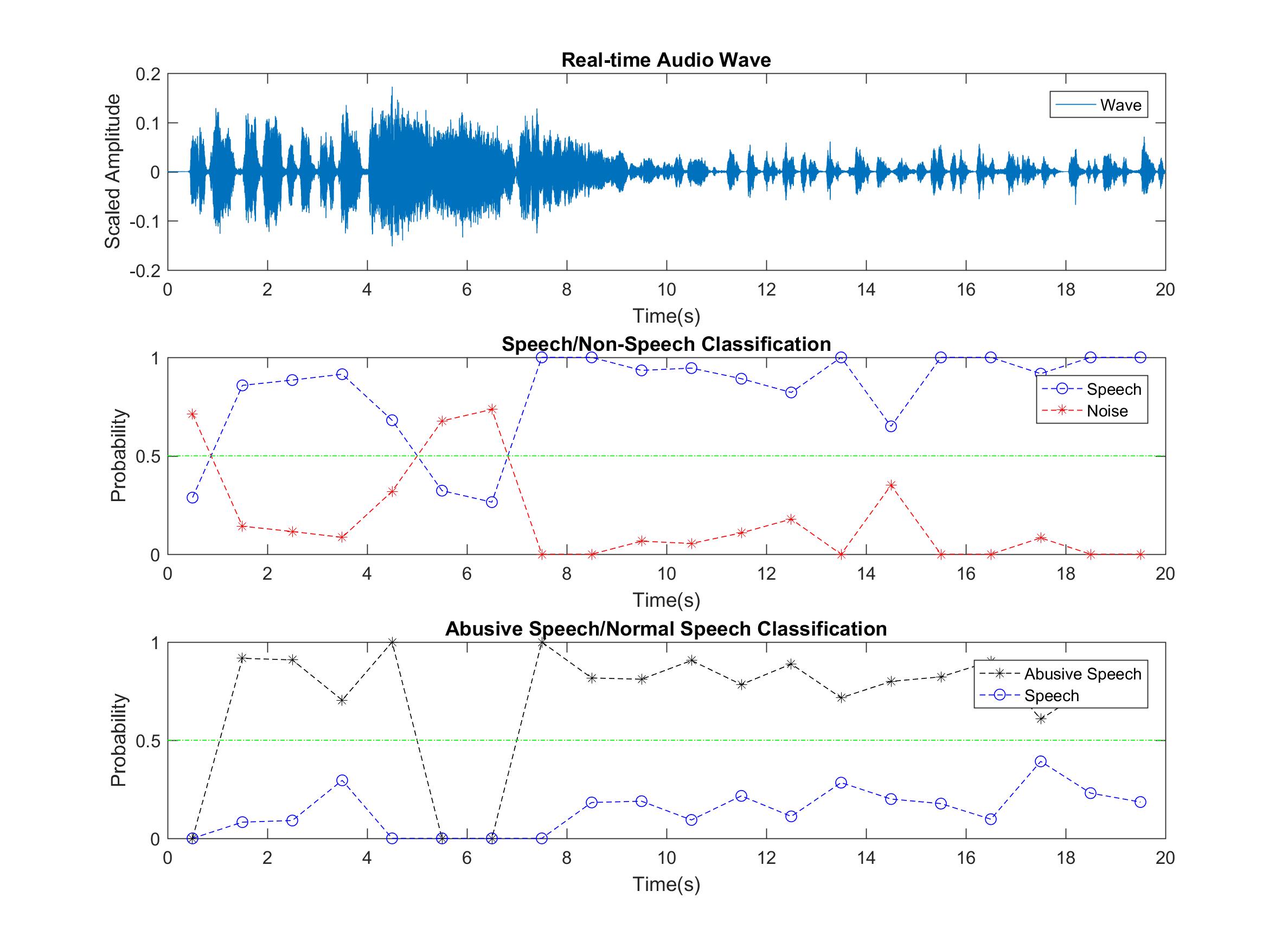
3.Open Matlab, Speak violently or broadcast an angry audio from phone. In this example the abusive classifier works well. But when I test it with my voice, it is hard to distinguish. Due to the fact that most of training audios are scream shouting, my low male voice is hard to classify when I speak violently.

All my training data are uploaded this this Dropbox link: https://www.dropbox.com/sh/ysphojpsy0gy1i0/AACPxTSIqPiRnOBROvT6Ee6Sa?dl=0
The training data comes from different databases, and I use matlab to change sampling frequency and nbits. All my training audios have been transferred to 16000 kHz and 16 nbits (see Training and Testing by User Section). It can be regarded as audio compression because some audios are 44100kHz or 22050kHz.
In speech / environmental noise identification, there are around 1000 files for each class. The comments help you find the corresponding folder after you download the whole datasets.
| Class | Description | # of files | Database | Comments |
|---|---|---|---|---|
| Speech | Voice on phone | ≈350 | http://www.speech.cs.cmu.edu/databases/pda/ | Very clear speech via phone |
| Speech | Daily speech | ≈100 | https://github.com/amsehili/noise-of-life | Use ‘speech’ folder |
| Speech | Daily speech | ≈50 | https://freesound.org/search/?q=speech&f=&s=score+desc&advanced=0&g=1 | Search ‘speech’ |
| Speech | ‘A’ ‘E’ ‘I’ ‘O’ ‘U’ | ≈50 | https://github.com/vocobox/human-voice-dataset | Pronouncation for AEIOU |
| Speech | Male/female/baby scream or cry | ≈200 | https://github.com/amsehili/noise-of-life | Use ‘maleScream’ ‘femaleScream’ ‘babyCry’ ‘femaleCry’ |
| Speech | Scream, shout | ≈50 | https://www.freesoundeffects.com/free-sounds/human-sound-effects-10037/ | Search ‘scream’,’shout’ |
| Speech | angry abusive speeches | ≈200 | https://freesound.org/search/?q=abusive&f=&s=score+desc&advanced=0&g=1 | Search ‘f*ck’, ‘sh*t’,’abusive’,’cursive’… Be ready for a mental pollution… |
| Noice | Noise in life(animals, music, cars, alarms, machines…) | ≈800 | https://github.com/karoldvl/ESC-50 | Randomly choose some |
| Noice | Noise indoor (breath, yawns, keyboards, electronic devices…) | ≈200 | https://github.com/amsehili/noise-of-life | Use ‘breathing’,’doorClapping’,’electricalShalver’,’hairDryer’,’handsClapping’,’keyBoards’,’Keys’,’Music’,’Water’,’yawn’ |
In speech / abusive speech identification, there are around 400 files for each class. The comments help you find the corresponding folder after you download the whole datasets.
| Class | Description | # of files | Database | Comments |
|---|---|---|---|---|
| Abusive Speech | Male/female/baby scream or cry | ≈200 | https://github.com/amsehili/noise-of-life | See ‘BabyCry’ ‘FemaleCry’ ‘FemaleScream’ ‘MaleScream’ folder in this repo |
| Abusive Speech | angry abusive speeches | ≈200 | https://freesound.org/search/?q=abusive&f=&s=score+desc&advanced=0&g=1 | Search ‘f_ck’, ‘sh_t’,’abusive’,’cursive’… Be ready for a mental pollution… |
| Normal Speech | Randomly choosen speeches | ≈400 | from ‘Voice on phone’ and ‘Daily speech’ above | Randomly choosen files |
The name of models follows ‘Date + usage + features + filter + statistics’. For example, model_11_12_speech_abuse_MFCC_filter_6stats means that the model used all 6 statistics (max/min/mean/median/standard deviation/ std divided by mean) of MFCC feature with noise filter and is used for abusive speech detection.
The KNN model finds k (=10) nearest audios in training datasets and makes the decision. After following instructions in Installation and running the code, you shall have outputs [recorder,samples,label1, P1, trainchosen1, label2, P2, trainchosen2, calc_time] in your workingsheet. The trainchosen1 and trainchosen2 stores indices of chosen traning files for 2 classifier.
Go to file my_code_real_time.m ‘s section check chosen file names. Paste the code in your console:
[~, ~, ~, classNames1, FileNames1] = kNN_model_load(modelSpeech_Non);
for i= 1:length(trainchosen1)
['in second' num2str(i), classNames1{1},' is identified according to']
FileNames1{1}(trainchosen1{i,1})
end
Now, the selected training audios to identify class 1 (‘speech’ in this case) will be outputed. Also, you can paste this to see selected audio samples to detect class 2 (‘noise’ in this case)
for i= 1:length(trainchosen2)
['in second' num2str(i), classNames1{2}, 'is identified according to']
FileNames1{2}(trainchosen1{i,2})
end
And then you will know which files are chosen for your speech/noise identifier. It is important for testers to know, because some bad examples will have side effects. I found that some training files with weak voice will mislead your identifier to regard your speech as noise, while some training files with songs will misguide your identifier to treat noise as human speech.
For example, if you want to test whether ‘spectral flux + ZCR + Energy Entropy’ features work better than ‘spectral flux + ZCR’ which I choose for speech/noise detection, then copy model_11_12_speech_S_Flux_ZCRE_Entropy_filter_6stats.mat file from models folder to your current directory.
Follow the instructions in Installation and running the code but remember to change your model’s name:
modelSpeech_Non = 'model_11_12_speech_S_Flux_ZCRE_Entropy_filter_6stats.mat';
Users may be more interested in training their own model based on their own collected audios.
Go to my_code_real_time.m‘s train a KNN-model with desired features + stats section. Specify your desired features at Feature_Names variable, if I want Zero-Cross_rate and Energy, then I will write
Feature_Names = {'ZCR','E'}
All features are listed here {‘ZCR’,’E’,’E_Entropy’,’S_Centroid’,’S_Spread’,’S_Entropy’,’S_Flux’,’S_Rolloff’,’MFCC_01′,’MFCC_02′,’MFCC_03′,’MFCC_04′,’MFCC_05′,’MFCC_06′,’MFCC_07′,’MFCC_08′,’MFCC_09′,’MFCC_10′,’MFCC_11′,’MFCC_12′,’MFCC_13′,’H_Ratio’} Also, remember to change the directory where you save your traning audios:
strDir = path to 'speech/noise' folders or 'speech/abuse' folders;
Paste the section in console and you will get a new ModelName.mat file.
stWin=0.05; stStep=0.05; % there will be 20 elements in each window
mtWin=1.0; mtStep=1.0; % our discriminative window is 1s
filter_dec = true; % Remeber to double check it
Statistics = { 'mean', 'median' , 'min' , 'max' , 'std' , 'std / mean'}; % 6 stats, you can change
Feature_Names = {'H_Ratio','MFCC_01','MFCC_02','MFCC_03','MFCC_04','MFCC_05','MFCC_06','MFCC_07','MFCC_08'...
'MFCC_09','MFCC_10','MFCC_11','MFCC_12','MFCC_13'}; % there are 22 features for you to choose
modelFileName = ['new_model_11_12_speech_abuse_MFCC_H_Ratio_filter_6stats.mat']; % remember to change model name to your desired one
strDir = 'C:\Users\Zhiyuan Li\Desktop\Prof_Ashish_Goel\training_data\speech_abuse\'; %remember to change folder directory
kNN_model_add_class(modelFileName, 'abuse', [strDir 'abuse'], Statistics, Feature_Names, stWin, stStep, mtWin, mtStep,filter_dec); % remember to change the class 1 to your desired one
kNN_model_add_class(modelFileName, 'speech', [strDir 'speech'], Statistics, Feature_Names, stWin, stStep, mtWin, mtStep,filter_dec);% remember to change the class 2 to your desired one
Audios may be in different sampling frequency and differnt nbits. So I write a matlab script to unify them.
Open my_code_change_audio.m. Go to check Fz and bits of audios section and change the path to the directory where you download your audios. Paste the codes in console
clear all;% close worksheet
clc;% close console
fclose('all'); % close all open files
path= 'C:\Users\Zhiyuan Li\Desktop\Prof_Ashish_Goel\training_data\speech_non_speech\speech'; % remember to change your directory
[Bits, Fs, Channels, FileNames] = check_bits_Fz(path);
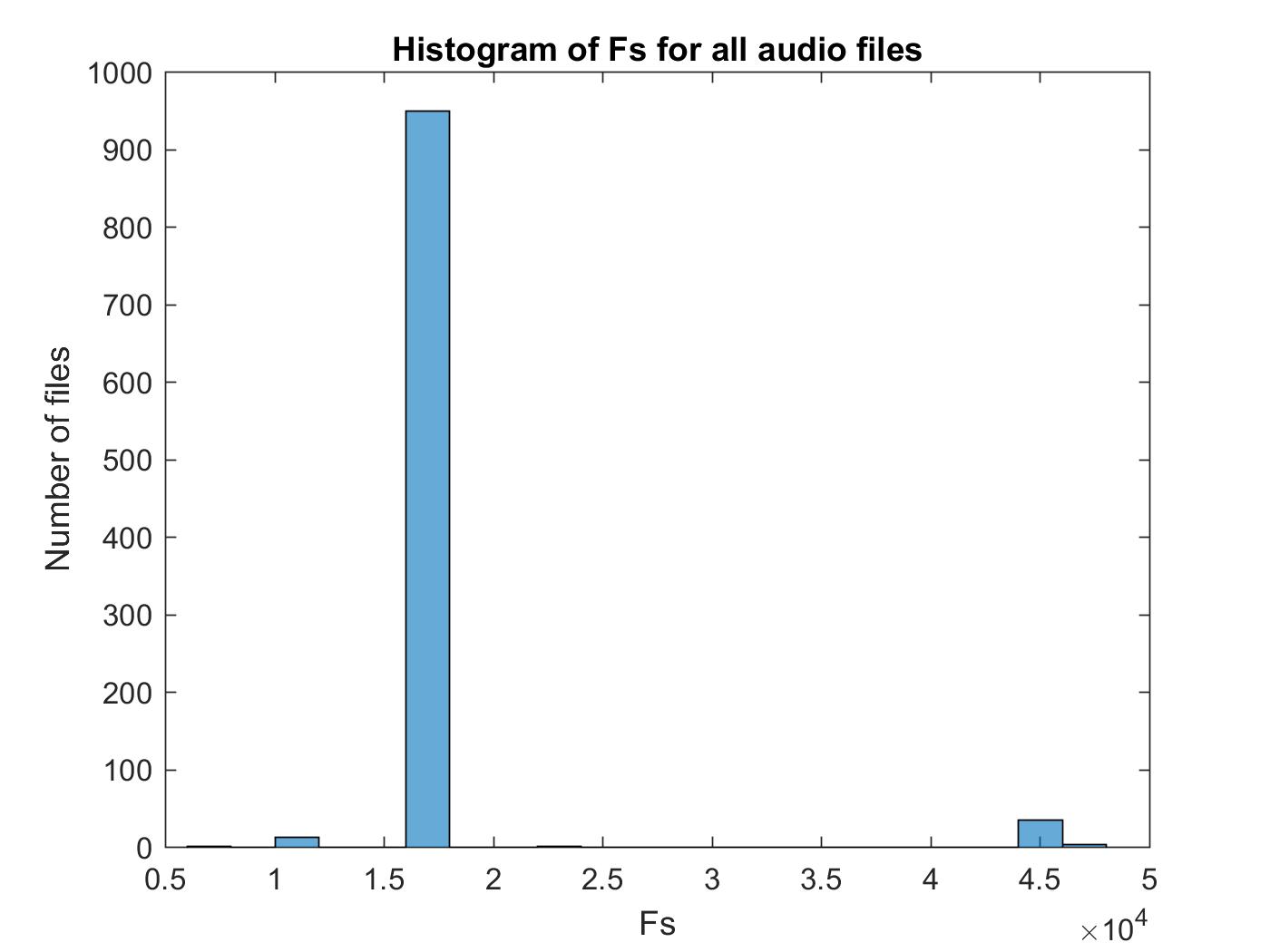
Now, plot the histogram and you will see how ‘nbits’, ‘sample frequency’ and ‘number of audio channels’ distrbute. Paste the code in plot distribution of Bit_temp & Fs_temp
figure;histogram(Bits)
xlabel('Bits');ylabel('Number of files');title('Histogram of Bits for all audio files')
figure;histogram(Fs)
xlabel('Fs');ylabel('Number of files');title('Histogram of Fs for all audio files')
figure;histogram(Channels,'BinWidth',1)
xlabel('Channels');ylabel('Number of files');title('Histogram of Channels for all audio files')
You will get three histograms, one of them is as following:

Now, go to section change Fs, bites(), specify the directory for your audios and the directory where you want to save new audios. You will change them to your desired sampling frequency and nbits by paste those codes from section change Fs, bites() into console:
Fs_new = 16000; % New Fs, for those audios with Fs<Fs_new, they will be omitted
bit_new = 16; % New bit
path= 'C:\Users\Zhiyuan Li\Desktop\Prof_Ashish_Goel\training_data\speech_non_speech'; % remember to change your directory
pathNew= 'C:\Users\Zhiyuan Li\Desktop\Prof_Ashish_Goel\training_data\speech_non_speech\new'; % remember to change your directory and make sure this folder exists
change_bit_Fz(path,pathNew,Fs_new,bit_new);
Your desired files will be generated in your new working directory.
- Jim Zhiyuan Li – Initial work Email: zhiyuan.li1995@hotmail.com
- Thanks for Theodoros Giannakopoulos’s Matlab Audio Analysis Library and his wonderful book (https://www.elsevier.com/books/introduction-to-audio-analysis/giannakopoulos/978-0-08-099388-1)
- Thanks for Professor Ashish Goel for this giving project.Thanks for advice from Nikhil Garg, Sukolsak Sakshuwong and Lodewijk Gelauff during weekly meetings.
 https://github.com/zhiyuan8/speech_detection
https://github.com/zhiyuan8/speech_detection
Leave a Reply